
kang's study
16일차 : 심층 신경망 본문

In [1]:
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
In [2]:
from sklearn.model_selection import train_test_split
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
In [3]:
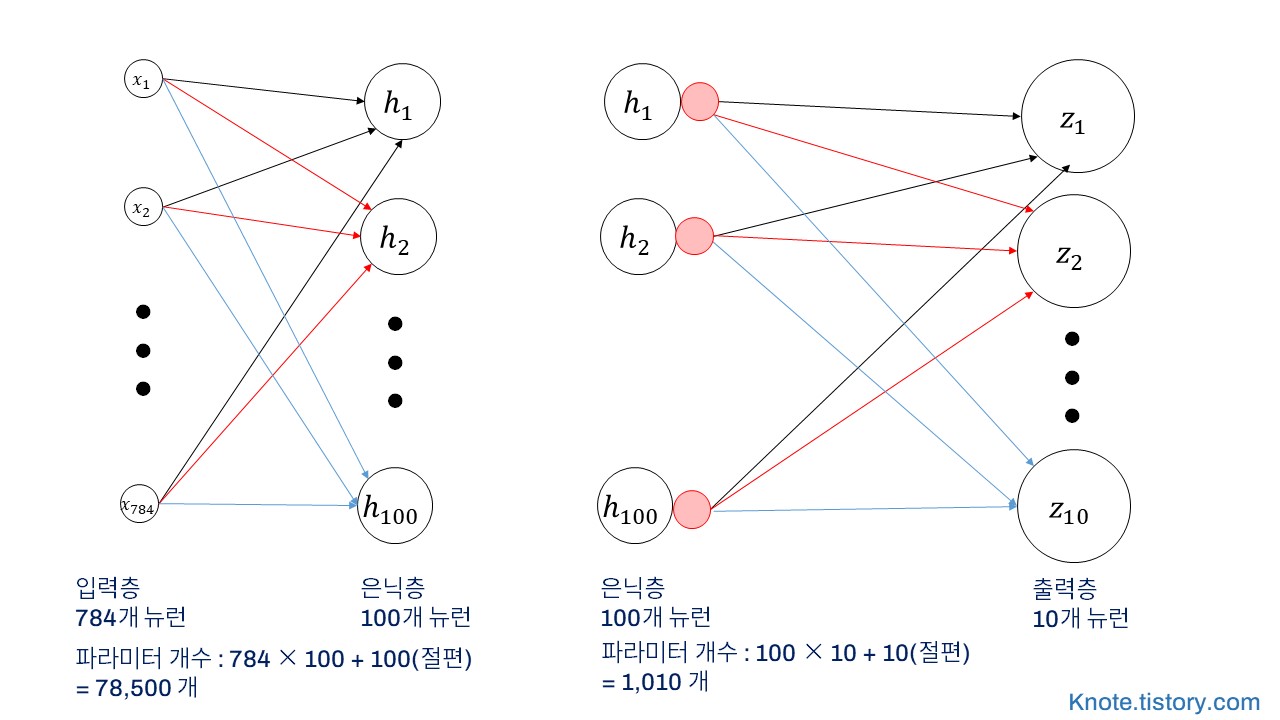
dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,))
dense2 = keras.layers.Dense(10, activation='softmax')
심층 신경망 만들기
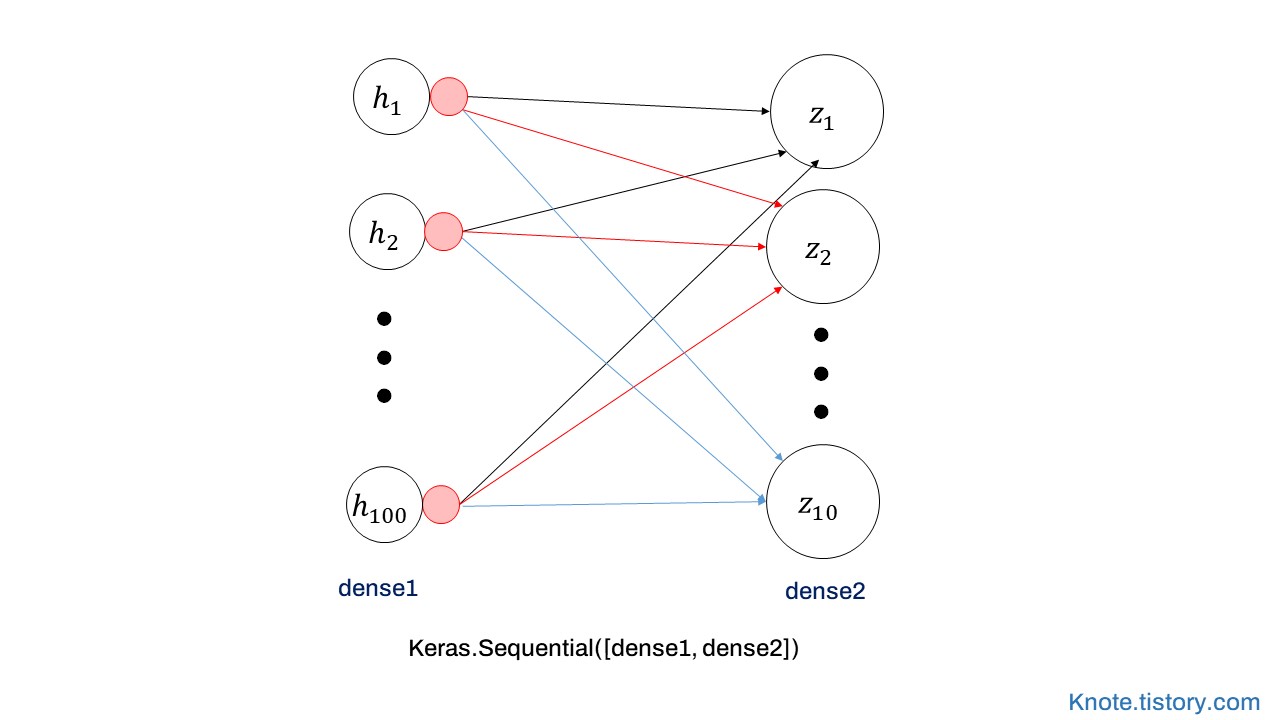
In [4]:
model = keras.Sequential([dense1, dense2])
In [5]:
model.summary()
# None은 fit모델에 batchsize 기본 32이다 미니배치하강법이다.
# 보통 64,128로 변경
# Param 각층에 있는 가중치와 절편의 개수
층을 추가하는 여러 방법¶
In [6]:
# 첫번째 방법
model = keras.Sequential([
keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'),
keras.layers.Dense(10, activation='softmax', name='output')
], name='패션 MNIST 모델')
In [7]:
model.summary()
In [8]:
# 두 번째 방법
model = keras.Sequential()
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)))
model.add(keras.layers.Dense(10, activation='softmax'))
In [9]:
model.summary()
모델 훈련¶
In [10]:
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
Out[10]:

In [11]:
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
# 케라스 편의를 위해 만든 층 데이터를 1차원 배열로 펼치는 작업을 수행해줌
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
In [12]:
model.summary()
In [13]:
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
In [14]:
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)
Out[14]:
In [15]:
model.evaluate(val_scaled, val_target)
Out[15]:

In [16]:
# 방법 1
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics='accuracy')
# 확률적 경사 하강법
In [17]:
# 방법 2
sgd = keras.optimizers.SGD()
model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics='accuracy')
In [18]:
# 설정을 따로 주고 싶다면 객체를 사용하는 방법을 사용
sgd = keras.optimizers.SGD(learning_rate=0.1)
In [19]:
sgd = keras.optimizers.SGD(momentum=0.9, nesterov=True)
# 수식을 이해해야함 중급서 (향후 핸즈온머신러닝 참고)
In [20]:
adagrad = keras.optimizers.Adagrad()
model.compile(optimizer=adagrad, loss='sparse_categorical_crossentropy', metrics='accuracy')
In [21]:
rmsprop = keras.optimizers.RMSprop()
model.compile(optimizer=rmsprop, loss='sparse_categorical_crossentropy', metrics='accuracy')
In [22]:
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
adam을 설정해서 모델 훈련해보기¶
In [23]:
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
# 옵티마이저, learning_rate는 하이퍼 파라미터이다.
model.fit(train_scaled, train_target, epochs=5)
Out[23]:
In [24]:
model.evaluate(val_scaled, val_target)
Out[24]:
출처 : 박해선, 『혼자공부하는머신러닝+딥러닝』, 한빛미디어(2021), p367-388
'[학습 공간] > [혼공머신러닝]' 카테고리의 다른 글
| 18일차 : 합성곱 신경망 (0) | 2022.03.03 |
|---|---|
| 17일차 : 신경망 모델 (0) | 2022.03.03 |
| 15일차 : 인공신경망 ANN, Artificial neural network (0) | 2022.03.03 |
| 14일차 : 차원축소 (0) | 2022.03.03 |
| 13일차 : k-평균 (0) | 2022.03.03 |
'[학습 공간]/[혼공머신러닝]' Related Articles
more



Comments